
SMS texting is frozen in time.
People still use and rely on trillions of SMS texts each year to exchange messages with friends, share family photos, and copy two-factor authentication codes to access sensitive data in their bank accounts. It’s hard to believe that at a time where technologies like AI are transforming our world, a forty-year old mobile messaging standard is still so prevalent.
Like any forty-year-old technology, SMS is antiquated compared to its modern counterparts. That’s especially concerning when it comes to security.
The World Has Changed, But SMS Hasn’t Changed With It
According to a recent whitepaper from Dekra, a safety certifications and testing lab, the security shortcomings of SMS can notably lead to:
- SMS Interception: Attackers can intercept SMS messages by exploiting vulnerabilities in mobile carrier networks. This can allow them to read the contents of SMS messages, including sensitive information such as two-factor authentication codes, passwords, and credit card numbers due to the lack of encryption offered by SMS.
- SMS Spoofing: Attackers can spoof SMS messages to launch phishing attacks to make it appear as if they are from a legitimate sender. This can be used to trick users into clicking on malicious links or revealing sensitive information. And because carrier networks have independently developed their approaches to deploying SMS texts over the years, the inability for carriers to exchange reputation signals to help identify fraudulent messages has made it tough to detect spoofed senders distributing potentially malicious messages.
These findings add to the well-established facts about SMS’ weaknesses, lack of encryption chief among them.
Dekra also compared SMS against a modern secure messaging protocol and found it lacked any built-in security functionality.
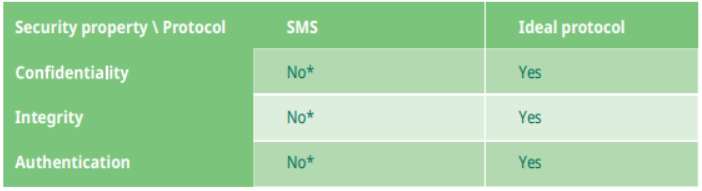
According to Dekra, SMS users can’t answer ‘yes’ to any of the following basic security questions:
- Confidentiality: Can I trust that no one else can read my SMSs?
- Integrity: Can I trust that the content of the SMS that I receive is not modified?
- Authentication: Can I trust the identity of the sender of the SMS that I receive?
But this isn’t just theoretical: cybercriminals have also caught on to the lack of security protections SMS provides and have repeatedly exploited its weakness. Both novice hackers and advanced threat actor groups (such as UNC3944 / Scattered Spider and APT41 investigated by Mandiant, part of Google Cloud) leverage the security deficiencies in SMS to launch different types of attacks against users and corporations alike.
Malicious cyber attacks that exploit the insecurity of SMS have resulted in identity theft, personal or corporate financial losses, unauthorized access to accounts and services, and worse.
Users Care About Messaging Security and Privacy Now More Than Ever
Both iOS and Android users understand the importance of security and privacy when sending and receiving messages, and now, they want more protection than what SMS can provide.
A new YouGov study examined how device users across platforms think and feel about SMS texting as well as their desire for more security to protect their text messages.

It’s Time to Move on From SMS
The security landscape as it relates to SMS is simple:
- SMS is widely used
- SMS is easily abused because it has so few protections
- Smartphone users across mobile platforms care more about security than ever before
The continued evolution of the mobile ecosystem will depend on users’ ability to trust and feel safe, regardless of the phone they may be using. The security of the mobile ecosystem is only as strong as its weakest link and, unfortunately, SMS texting is both a large and weak link in the chain largely because texts between iPhones and Androids revert to SMS.
As a mobile ecosystem, we collectively owe it to all users, across platforms, to enable them to be as safe as possible. It’s a shame that a problem like texting security remains as prominent as it is, particularly when new protocols like RCS are well-established and would drastically improve security for everyone.
Today, most global carriers and over 500 Android device manufacturers already support RCS and RCS is enabled by default on Messages by Google. However, whether the solution is RCS or something else, it’s important that our industry moves towards a solution to a problem that should have been fixed before the smartphone era ever began.


